RISC-Vのマルチコア化をやっていますが、1コアでも複雑極まりないプロセッサが2つになってデータの取り合いをするのですから、厄介極まりない事態となります。特にマルチコアでは複数のコアが同じデータを書き換えたりするので、適切な制御がないとデッドロックやデータの破損(異常値)が起こります。
ここではその厄介な状況に対処している仕組みや、実際に起こった厄介な事例の紹介をします。
具体的なマルチコアハードウェアの実装
1. キャッシュへの同時アクセスを防ぐ
スヌーピング機構があるため、キャッシュはプロセッサ自身の処理と、スヌーピングの2つからアクセスされます。このため、以下のような問題が発生します。
キャッシュのポート数によっては1サイクルに1つのプロセスしかキャッシュの読み書きができない
この場合、プロセッサ本来の処理とスヌーピングのどちらか一方しかキャッシュを使えません。そのため「どちらにキャッシュ使用権をあげるか」ということを管理し、一方を適切に待たせる必要があります。しかし単純に待たせ続けるだけでは計算速度が低下します。そのため次のような高速化が望まれます。
書き変えるのならともかく、読むだけならば同時にやりたい
相手がストアにより自分の知らない値に書き換えるのなら安全のため止まるのも良いですが、どちらも読む(ロードする)だけならば同時に行うこともできそうです。
これを可能にする実装方法の1つが、プロセッサ本体用とスヌーピング用にキャッシュデータを複製することです。同じ内容を書いたノートを2冊用意するということで、見るだけならば各自に割り当てられたノートを勝手に見ます。しかし誰かが内容を一部書き換えたいという場合は、他の全員が読み書きすることを止めて、許可された1人だけがすべてのノートの当該箇所を書き換えます。つまりこの時だけは相手を待たせてプロセッサ用、スヌーピング用の2つのキャッシュの同じデータAを書き換えます。
待ち時間は短くなりますが、待つという事態が発生することには変わりありません。そうなると次の疑問としては、
どの状況でキャッシュ使用権を待たせるのか、優先的に使用できる期間が必要か
という問題が出てきます。例えばメモリからのロードとスヌープへのデータ送信が同時に要求されている状況を考えます。この時プロセッサはキャッシュの[1a][00]~[1a][0f]という所にアドレス0x8000から始まるデータをロードしようとしていて、スヌープは丁度同じ[1a][00]~[1a][0f]にキャッシュ済みのアドレス0xc140から始まるデータを他のプロセッサに送ろうとしているとします。
例え1サイクルに1プロセスしかキャッシュを使えないように制限しても、もし2つのプロセスが1データごとに交互に交代してしまうと、
1. キャッシュ[1a][00]にメモリから0x8000がロードされる
2. スヌーピングが[1a][00]を送るが、これは0xc140でなく1サイクル前に書き換えられた0x8000を送っている
1. キャッシュ[1a][01]にメモリから0x8004がロードされる
2. スヌーピングが[1a][01]を送るが、これは0xc144でなく1サイクル前に書き換えられた0x8004を送っている
というように、全く想定外のアドレスをスヌーピングで送ってしまうという事態になりかねません。これを防ぐためには1度ロードを始めたら、終わるまで同じキャッシュライン領域に他のプロセス(スヌーピング)がアクセスすることを禁じるといった制限も必要となります。ACEバスには次節で紹介するようなアクセス制限もありますが、このようなCPU内やバスのスケジューリングでは実装依存で対処すべき制御も多く存在します。
2. ACEバスの同じアドレスの同時使用の禁止
ACEバスのプロトコルでは、同じアドレス(キャッシュライン)はある時点で1ユーザしか使えないという制限があります。これはどういうことかというと、もしRead系チャネルでアドレス0x8000のロードを行っていたら、Write系チャネルやSnoop系チャネルでは0x8000の使用をしてはならないということです。
具体的にはある1つのトランザクションがアドレス0x8000(を含むキャッシュライン)を使用していたら、それが終わるまではそのアドレスを使いたい他のトランザクションの発行は禁止されるという意味です。具体例は次章のバグの説明で触れますが、この制限がないと正しくないデータやキャッシュ状態が生じてしまうためです。
そのためインターコネクトはただ闇雲に要求のあったトランザクションを隙間なく許可するのではなく、ちゃんと開始してよいかを判断する必要があります。
マルチコア実装時に出会ったバグ
キャッシュ待ちやバスの割り当て機構を設計した時に、実際にどのようなバグに出会ったかの例を紹介します。
プロセッサ本来の処理のアドレスとスヌーピングのアドレスの混同
プロセッサ自身が行っているロード(lw)やストア(sw)の処理(以降、固有プロセス)と、他のプロセッサから来るスヌーピングで使われるアドレスは異なります。それら2つのプロセスが同時に来たらどちらのプロセスを先行させるかを決める必要があります。
ここではその調停機構にバグがあり、先行させたスヌーピングによるInvalidationが誤って固有プロセス用のアドレスを使っていました。
それを表したのが次の図で、スヌーピングで来たInvalidationは本来は0x7900を使用するはずですが、誤って固有プロセスのlw用の0x4040を使用し、0x4040のキャッシュデータをInvalidationしています。
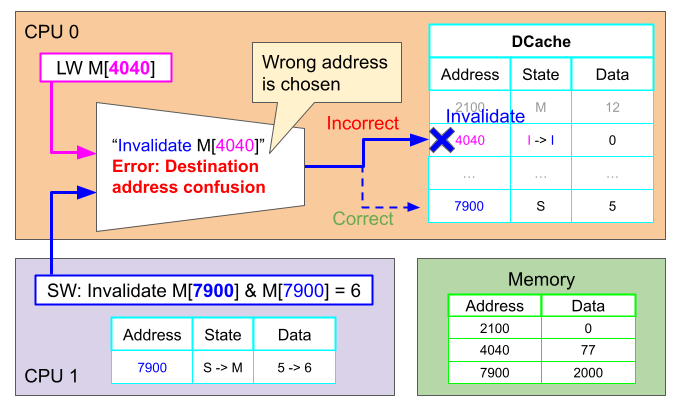
これにより全く別のデータがInvalidaitonされ、消されるべきだったCPU0の0x7900が生き残ってしまいます。しかしCPU0はInvalidationは完了したものと思い込んで完了報告を返すため、スヌーピングを送ったCPU1もvalidな0x7900は自分のところにしかないと思い込みます。このままCPU1がデータを書き換えると、
1. 2つのCPUが0x7900を共有しているのに、値が異なっている (5と6)
2. 2つのCPUで0x7900が共有されているのに、CPU1側はUnique状態(自分しか持っていない)のMで保持している
というキャッシュコヒーレンシの崩壊が発生します。
このため2つのプロセスからの使用要求が同時に来ても、アドレスやデータを取り違えないように注意する必要があります。
ACEバスでの複数のチャネルでの同時アクセス
ACEバスの同時アクセス制限に関わるバグです。ここでは全く同時アクセス制限がなされず、チャネルが空いていたらすかさず他のトランザクションが割り当てられるという実装にしていた場合です。
次の図の状況では、CPU0、CPU1がともにキャッシュミスしたAをロードしようとしています。ここで先にCPU0にSnoopチャネルの使用が割り当てられ(ピンク矢印)、CPU1にスヌーピングが行われますが、CPU1もキャッシュミスするため、諦めてReadチャネル(黄緑矢印)に移ってメモリからロードをしようとします。
しかしバスのバグにより、CPU0のメモリからのロードが終わっていないにも関わらずCPU1のSnoopチャネルの使用が始まりCPU0にスヌーピングが送られてしまいます。この時、まだCPU0はAを持っていないためスヌープミスとなり、CPU1もメモリからのロードをすることに決めます。最終的にどちらもメモリからロードしますが、どちらも「自分がスヌーピングしたとき相手は持っていなかったから、わざわざメモリからロードした自分のAはUnique状態だ」とAをUnique状態(MOESIのEかM)で保持します。1つのプロセッサしかUnique状態となれないため、これは誤りです。
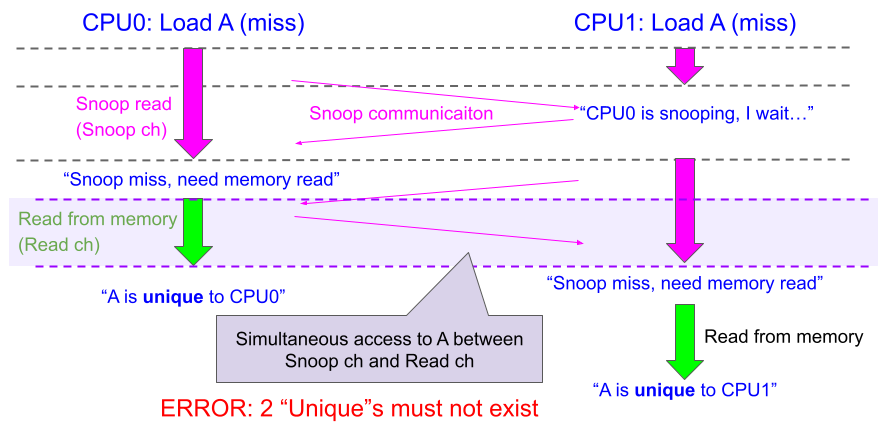
これを防ぐためには、あるトランザクションがアドレスAを使用していたら、たとえ使用されていないチャネルであっても他のプロセッサにはAを使わせないという制限をかける必要があります。
連続実行すべきチャネルの分割
データを取得するトランザクションでは複数のチャネルが使用され得ます。例えばデータを共有状態で取得するReadSharedトランザクションでは、まずSnoopチャネルで他のプロセッサから貰おうとし、他のプロセッサが持っていなければReadチャネルでメモリからロードします。この2つのチャネル使用の連携で1つの「共有しながらロードする」というロードを行います。そしてACEの制限としては、1つのトランザクション中に他のトランザクションが同じアドレスを使用することができません。
次の図の例ではアドレスAのロードをReadSharedトランザクションで行っています。同じサイクル時点ではAというアドレスは1つのチャネルでしか使用されていません。しかし、バスのバグにより複数のプロセッサが交互のチャネルを使用しているせいで、先行したCPU0の「トランザクション」が完了していない(=メモリからのロードが未終了)のにCPU1のスヌーピングが始まっています。
これにより互いに「スヌーピングしたけれど相手はAを持っていないから、メモリから自分がロードしてUniqueになる」と誤って判断してしまいます。それによりUnique状態が複数発生するというエラーにつながります。
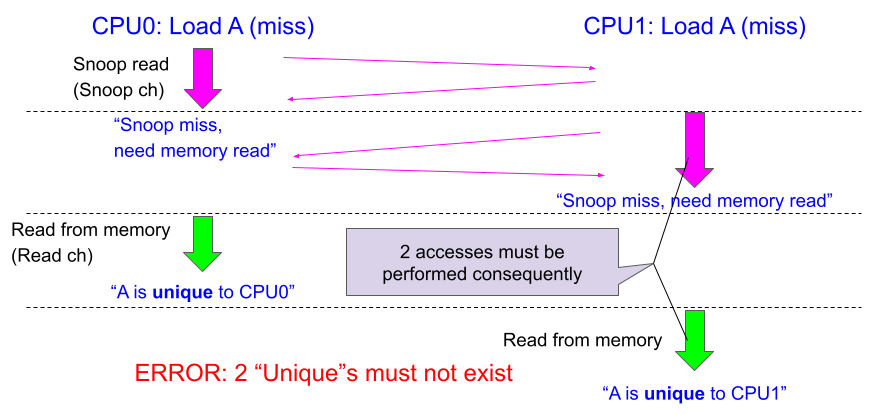
このため、後回しになるCPU1は、CPU0のメモリからのロードが完了するまでスヌーピングも待たせる必要があります。すなわちCPU0のReadSharedトランザクション(スヌーピング -> メモリからのロード によるAのロード)がすべて終わるまでは、例えチャネルが空いていても使用してはいけません。
ACEバスの実装は「あるサイクルでは1つのチャネルしかアドレスAを使えない」だけではなく、「複数のチャネルを使用する一連のトランザクションが終わるまでは、他のプロセッサのトランザクションはアドレスAを使えない」という点に注意が必要です。
書き換え前に共有が行われる
ACEプロトコルではトランザクションが終了したらプロセッサはRACKあるいはWACKという信号をインターコネクトに送ります。これは「トランザクションが完了したので、使っていたアドレスAを解放します」という信号です。インターコネクトはACKを受け取った後ではじめて、他のプロセッサが要求する同じアドレスAを使ったトランザクションを許可します。
InvalidationやSharedReadトランザクションはプロセッサのReadチャネルからの要求から始まるため、Read ACK (RACK)が完了時に送られます。しかしRACKを送信するのはあくまでも「ACEバスの使用」が終わったタイミングとされています。例えばInvalidationをして新しい値をキャッシュにストアする時、プロトコル上ではRACKを送るタイミングは「プロセッサがインターコネクトからInvalidation完了報告を受け取った時」とすることができ、プロセッサ上でのキャッシュへのストアより前にRACKを送っても問題ありません。
このInvalidation時に適切なRACKとキャッシュストアの制御ができていないバグあった例が次の図です。CPU0はUnique状態でAを値5で取得(緑矢印、Invalidationと読み替えも可)し、新しい値6をストアし「Dirty」状態に変更しようとします。
しかしこの時ACEバスの使用が終わった、すなわちA=5をロードした直後にRACKが送信されていて、CPU1のAのロードがすぐに始まってしまったとします。CPU0はCPU1からのスヌーピングを受けAを共有しますが、この時まだストアが終わっていないためCPU0は「Clean状態でスヌーピングされたから、データ送信によりSharedClean(MOESIのS)状態になる」と判断してしまいます。そのため本来はA=6にした後「Dirty」フラグが立っているべきなのに、「Clean」で上書きされてしまうという問題が発生します。これによりAに書き換えがあったという事実が見えなくなってしまいます。
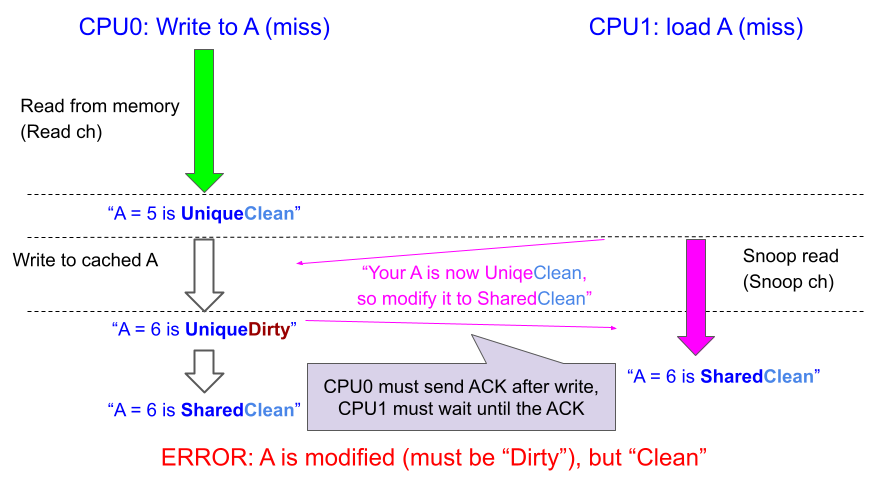
このケースでは他にも未ストアのA=5が共有されてしまったりCPU0がUniqueのままになり続けるといったエラーになることも考えられます。いずれにせよ問題なのが、自分のストアが終わっていないのに、他から来た同じアドレスへのスヌーピングに対応してしまっていることです。
そのため、スヌーピングが来ても自分のストア処理が終わるまで待たせる必要があります。これは次の2通りのいずれかの実装により可能です。
1. RACKを出すタイミングをキャッシュへのストア後に行う
2. RACKはInvalidation終了直後に出してインターコネクトがCPU1のスヌーピングを始めることは許すが、たとえCPU0にそのスヌーピングが来ても、CPU0は自身のストアが終わるまではスヌーピングへの対応をしない(返信を返さない)
このようにACEプロトコルだけでなく、実装依存で対処しなくてはならないタイミング問題も存在します。
