前回のマルチコア時に発生したバグや実装時の注意点の続きです。ここではLinuxを動かした際に出た、ハードウェアバグに関わるカーネルパニックや厄介なエラーを見ていきます。
またそんなバグを特定するために作ったデバッガの紹介もします。
カーネルの初期化プロセスのエラーが後になって判明する例
Linuxのような大規模なプログラムを実行すると、エラーがすぐに表面化しない例が多々あります。ここではAMO命令を行うハードに単純なバグがあり、それが後々に面倒なエラーを引き起こす例を紹介します。
カーネルの初期化プロセスでは、1つのプロセッサのみが行う領域が存在します。この領域に入るかどうかはAMO命令によって管理されていて、最初に到達したプロセッサだけが入ることを許されます。その時AMO命令によりアドレスAが初期値ゼロから非ゼロの値にセットされます。しかしこの時バグがありAが初期値ゼロのままだと他のプロセッサも入ることが許されてしまい、1つのプロセッサしか実行しない初期化プロセスを複数のプロセッサが実行することになります。
ただ、この時点ではまだ大きな問題、すくなくとも直後にPCが止まったりエラー文が出るような「気づきやすい」エラーとはなりません。複数のプロセッサにより初期化プロセスがどんどん実行され、しっちゃかめっちゃかになってから初めて「Ebreak」というエラーとしてコンソールに表示されます。
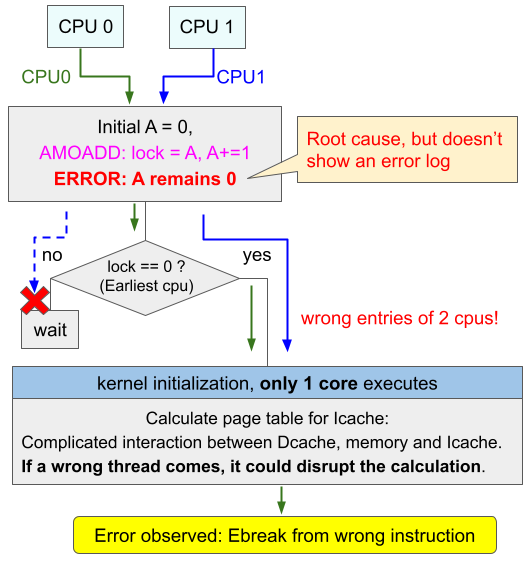
あくまで最初のAMOこそが問題であり、そのしっちゃかめっちゃかの事態そのものは重要ではないのですが、この時最終的に起こっているのは「ありえないアドレスにある命令をフェッチしろと言われた」というエラーです。これは次のようなハードとタイミングの問題が絡み合う複雑なエラーです。
- 初期化プロセスに誤って2つのプロセッサが入ってくる
- 初期化プロセスでは命令フェッチのための命令側のページングで使うためのデータAをロードし、値をA’に書き換えようとする
- CPU0がAをロードしA’に書き換える
- この時誤って入ってきたCPU1も同じことをする。スヌーピングによりCPU0のA’をInvalidationして、かつA’をもらう。A’をA’に書き換える
- 本来は1つのCPUじか実行しないプログラムのため、CPU0のプログラムは「現時点ではこのCPUは自分でAを書き換えてA’を持っている」ことを前提としている。この「A’」を命令キャッシュに渡そうとする
- プログラムは命令キャッシュにはスヌープ機構がないこと(実装としてはあり得る)を想定し、一度「A’」をメモリにWBしようとする。RISC-Vのfence命令により強制的にデータキャッシュのWBが行われる
- この時実はCPU0はInvalidaitonによって「A’」は持っていない。そのためA’はメモリにWBされず、メモリがもつAはAのままである
- CPU0のプログラムはfence命令が終わったら「メモリはA’を持っている」ことを前提としている。これを命令キャッシュに読み込ませる
- 命令キャッシュがロードするのは書き換え前の「A」である。そのためプログラムの想定とは全く違う値のデータが命令フェッチで使われることになり、Ebreakを引き起こす
本来解決すべきバグは元凶のAMO命令のバグです。しかしそこに気づけないとこの二次的なややこしいエラー解析に時間を食うことになります。さらにこの二次的エラーを「解決」しようとして、「じゃあ命令キャッシュ側にもスヌーピング機構を付けてA’をCPU1からもらえるようにしよう」といった「間違った解決策」が取られる可能性があります。それにより今回の二次的エラーは回避できるようになるかもしれませんが、根本的なAMOのバグは残ったままになってしまいます。
アドレス変換のバグによるカーネルスレッドの停止
ハード編ではRISC-Vのアドレス変換の実施は2通りの方法で制御されると書きましたが、もし一方のCSR:mstatusのMPRVビットによるアドレス変換の実施ができていない場合に起こるのがこのエラーです。
RISC-VのLinuxではカーネルスレッド間でソフトウェア割り込みをかけることで、スレッド同士が連携しています。そのため割り込みがないとスレッドが待ちぼうけとなってしまいます。
このソフトウェア割り込みはCLINTを介して行われます。CLINTにどのプロセッサに割り込みしたいかのデータを渡すことで、CLINTが割り込みを通知します。この時、CLINTへのアクセスはマシンモード(アドレス変換無し)で行われます。一方でCLINTに渡したいデータはスーパバイザモード(アドレス変換有り)で作られたものです。そのためCLINTへと送るデータをロードする時には、一時的にアドレス変換を行い、スーパバイザモードで用意されたデータを見に行く必要があります。この一時的なアドレス変換にMPRVビットによるアドレス変換が使われます。
そのため、MPRVビット判定にバグがあり、このアドレス変換が行われないとCLINTへ送るデータを適切に取得することができません。次の図では、Proc0がCLINTに「仮想アドレス0xC0A0」のデータを送ろうとしています。0xC0A0は仮想アドレスであり、その物理アドレスは0x80A0です。そこには「Proc2に割り込みをかける」ことを意味する1ビット目が1になったデータがあります。CLINTへ渡すデータはこの0x80A0をロードする必要があるのですが、バグによりアドレス変換が働かず、0xC0A0のまま物理ロードを行ってしまいます。
これにより全く違う”物理”アドレス=0xC0A0からデータがロードされてしまい想定外の値がロードされます。今回は値がゼロとなっていて、どこにも割り込みを書けないという意味になってしまいます。そのためソフトウェア割り込みが発生せず、割り込みを待っているスレッドはやることが無くなってしまい、仕方なくヒマなプロセッサの集合場所であるPID:0のアイドルスレッドに帰ってしまいます。そのためいつまで経ってもブートが終わりません。
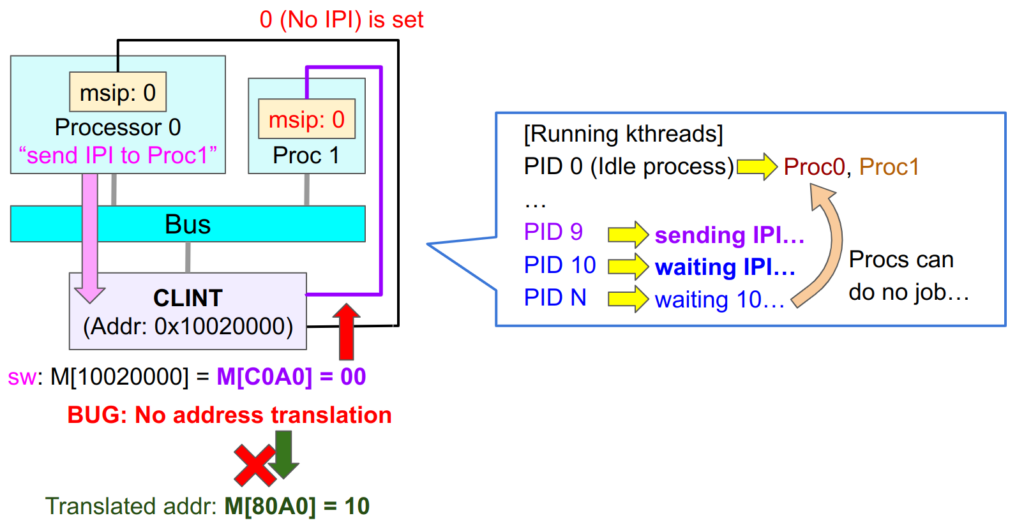
このエラーの嫌なところは、明確なエラー文は全く出ず、PCも遷移してスレッドスケジューリングは適切に動いている(正常に「できる仕事がない」ということを判断)ため、一見すると完全に正常に動いているように見えることです。それにも関わらず、なぜかプロセッサが皆次々に、正常な「君に紹介できる仕事はない」というスケジューリングにより職を失っていきます。確認しようにも相手はLinuxのスケジューリング機構やカーネルスレッドの状態管理という大迷宮のため、容易に中を覗くこともできません。
そのためこのエラーの発見には使用される物理アドレスの監視が有効です。今回の状況だと、仮想アドレスのままの0xC0A0が物理アドレスに使用されています。そのため物理アドレスとして使われるはずのないアドレスの値を見つけたら直ちにエラーを出力させることで、バグの早期発見が可能です。
riscv-gnu-toolchainとLinuxのバージョンの齟齬によるエラー
これは純粋にソフト的なエラーです。ソフト編で紹介したクイックソートを実行したら、
The futex facility returned an unexpected error code.というエラー文が出てきました。futexはfast mutexの略でpthreadで使われるものです。研究室の詳しい方に教えてもらったところ、ビルドツールと使用しているバージョンのLinuxシステムコールが不一致なことが原因でした。
このエラーが起こった時、自分はLinux-v4.20を使っていたのですが、このv4.20では、futex関連のシステムコール番号は次のように1つだけ定義されていました。
// in linux/include/uapi/asm-generic/unistd.h
/* kernel/futex.c */
#define __NR_futex 98
__SC_COMP(__NR_futex, sys_futex, compat_sys_futex)一方でv5等のより新しいLinuxでは、
#define __NR_futex_time64 422
__SYSCALL(__NR_futex_time64, sys_futex)のようにfutex関連でfutex_time64というものも追加されています。
一方、riscv-gnu-toolchainのglibcでは「__ASSUME_TIME64_SYSCALLS」というものが定義されていて、これによりfutex関連の関数を呼び出すと、「__futex_abstimed_wait_common64()」という関数が呼ばれます。
// glibc/nptl/futex-internal.c
static int __futex_abstimed_wait_common ()
{
#ifdef __ASSUME_TIME64_SYSCALLS
err = __futex_abstimed_wait_common64 (futex_word, expected, op, abstime,
private, cancel);
#else
err = __futex_abstimed_wait_common32 (futex_word, expected, op, abstime,
private, cancel);
#endif
}新しいLinuxでは「__NR_futex_time64 422」というものを持っていますが、古いv4.20だと「__NR_futex 98」しか持っていません。そのためglibcの~~common64()に適切に対処できないようです。これにより以下でglibcがエラーを出力します。
static __always_inline __attribute__ ((__noreturn__)) void
futex_fatal_error (void)
{
__libc_fatal ("The futex facility returned an unexpected error code.\n");
}
static __always_inline int
futex_wait (unsigned int *futex_word, unsigned int expected, int private)
{
int err = lll_futex_timed_wait (futex_word, expected, NULL, private);
switch (err)
{
case 0:
case -EAGAIN:
case -EINTR:
return -err;
case -ETIMEDOUT: /* Cannot have happened as we provided no timeout. */
case -EFAULT: /* Must have been caused by a glibc or application bug. */
case -EINVAL: /* Either due to wrong alignment or due to the timeout not
being normalized. Must have been caused by a glibc or
application bug. */
case -ENOSYS: /* Must have been caused by a glibc bug. */
/* No other errors are documented at this time. */
default:
futex_fatal_error ();
}
}古いLinuxバージョンを使うためにriscv-gnu-toolchainをインストールし直すのは面倒なため、新しいv5.10.99を使うようにしたら、正常にpthreadが動作しソートができるようになりました。
マルチコア用のデバッガを作ってみた
どんなデバッガがほしいか
これまで見てきたエラーで多いのが、MOESIキャッシュ状態がおかしかったり、ヘンな値が入っているというケースです。これらのエラーはプロセッサがスヌーピングやバスの取り合いのような相互作用をする過程で起こっています。そのため、個々のデータ変更を見るのではなく、ある命令が引き起こしうる一連のデータ変更全体が正しいかを検証するのが有効そうです。
スヌーピングやバスによりどのようなデータ変更が行われるかを見通しよく把握するには、次の図の左のような抽象的な命令の定義を考えるのではなく、ハードウェアを考慮して命令の意味を拡張することが有効です。例えばストア命令:swの場合、ただ定義通りの「メモリを書き換える」のではなく、「Invalidationを行い、スヌーピングで最新の値を取得し、キャッシュ上にストアする」とシステム全体で何が起こるかを考えます。
この視点により、1つのロードやストア命令はSIMD命令のように様々なデータが連鎖的に書き換えると命令を捉え直します。
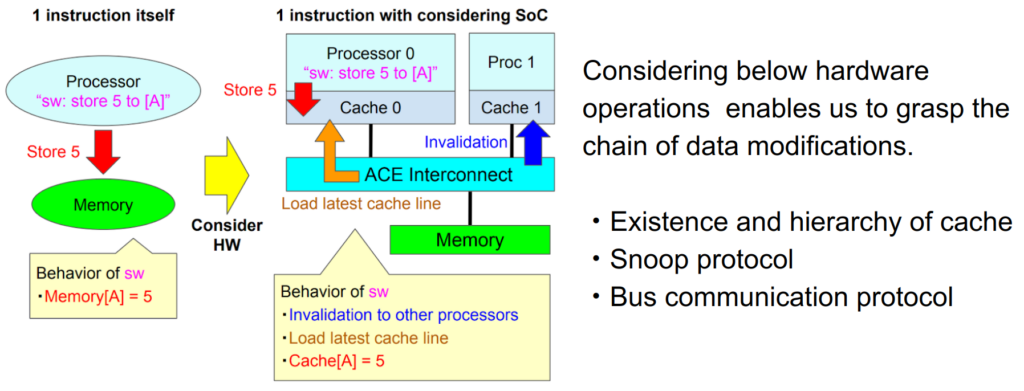
システム全体でのデータ変更を検証するデバッガ
このような検証を行うデバッガを作製しました。
やってることとしては、
1. 各プロセッサのキャッシュやメモリのデータの情報を集めて、
2. 「アドレスAのデータは今誰が、それぞれどの状態や値で持っているか」ということを整理して、
3. 各ロードやストア命令によるデータ書き換えや移動が、ACEプロトコルとかで想定される結果と一致するかを検証する
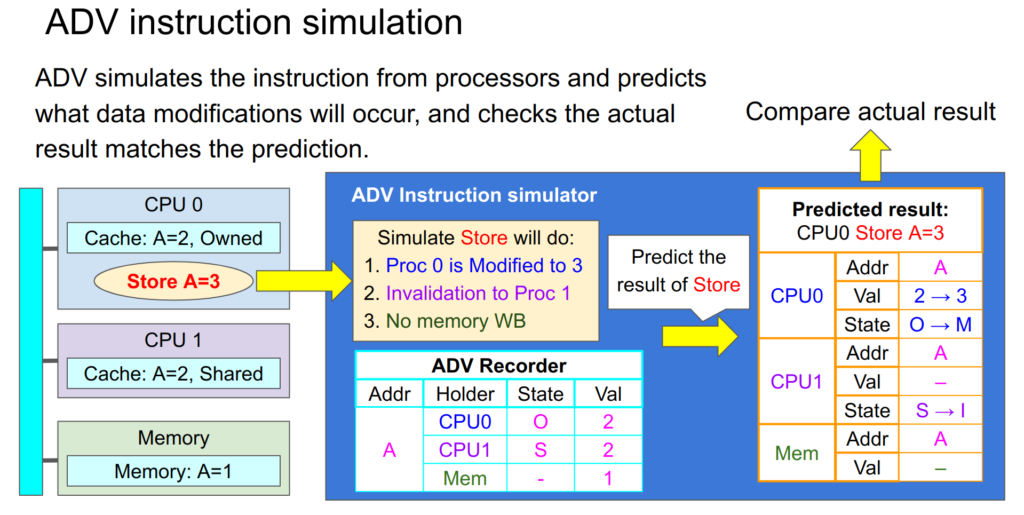
デバッガです。データを収集するので、カッコよくAssembled Data Verifier (ADV)とか名付けてみました。
下の図は2コアのシステムで、各プロセッサはそれぞれデータキャッシュを持っています。例えばアドレス1000~103cのデータを含むキャッシュラインは、CPU0、CPU1で共有されています。このラインはCPU0が書き換えを何度か行っていて(WBはまだ)、それがCPU1に共有されています。
この場合、ADVは「アドレス1000~103cのデータの値はそれぞれab,cd,…,00で、CPU0はO状態、CPU1はS状態で保持している」ということを記録しています。他のキャッシュラインについても誰がキャッシュしているか等の情報を収集しています。
またプログラム実行開始前にあらかじめプログラムを読み込んでおき、メモリのデータを取得しています。
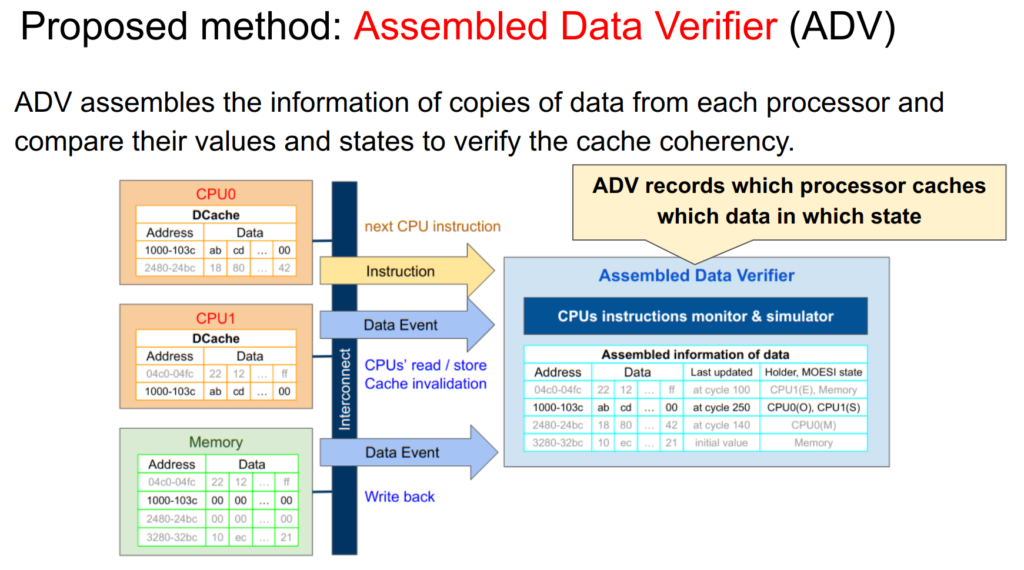
そしてADVはデータの情報を集めるとともに各プロセッサが次にどのような命令を実行する予定かを監視しています。もしそれがロードやストアといったメモリアクセス命令なら、その命令をシミュレーションし、現在ADVに格納されているAの情報を元に、どこでどのようなデータ変更が起こるかを予測します。
次の図ではCPU0がAに値3をストアしようとしています。ADVはAは今CPU0にO状態で、CPU1にS状態でキャッシュされているということを収集した情報から知っています。この時CPU0のストア命令を検知すると次のことが起こると予測します:
1. CPU0のキャッシュしているAの値は3になり、Modified状態になる
2. CPU1のキャッシュしているAはInvalid状態になる
3. メモリへのWBは起こらない
この予測とストア命令終了までに実際に起こった変更を比較し、データ変更がすべて予測されたものに一致するかを検証します。これによりCPU0内部だけでなく、他のシステム全体でも正しい変更が起こったかを検証します。ある意味、SIMD命令の検証と言えます。
ADVは各CPUごとにシミュレーションを行います。例えばCPU0がAのロードをするつもりで、同時にCPU1がBへのストアをしようとしていたら、CPU0、CPU1それぞれの命令ごとに別個のシミュレーションを行います。
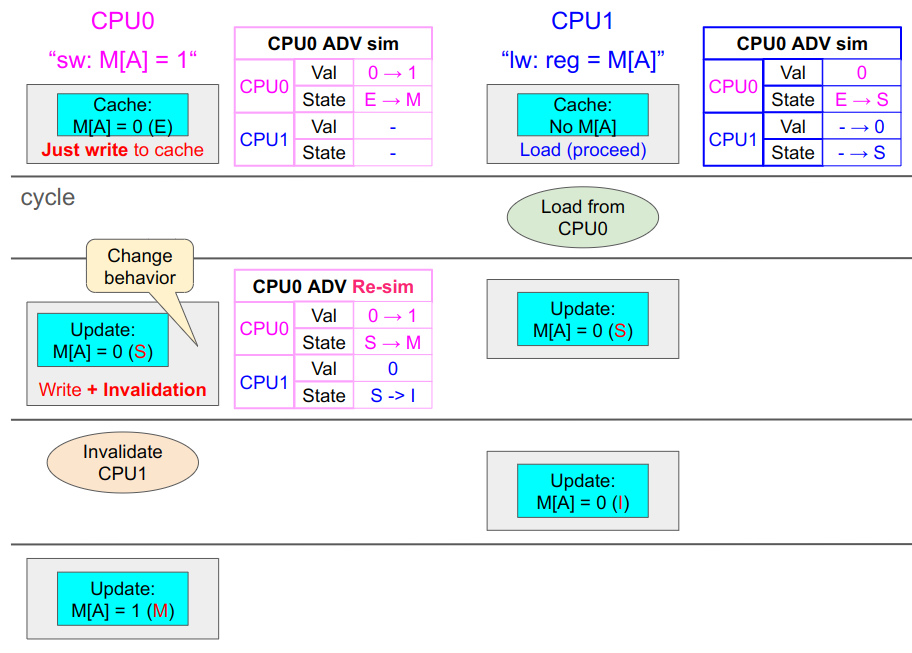
デバッガの実装: 同時アドレスアクセスへの対応
このデバッガでは対処しなくてはいけない点があり、それが複数のプロセッサが同時に同じアドレスを使う(同時アクセス, Simultaneous Access, SA)場合です。例えば以下の図ではCPU0はAへのストアを、CPU1はAのロードをしようとしています。ADVもそれに合わせて別個にシミュレーションしています。
ここで、もしCPU1が先行してロードをした場合は、CPU1側のシミュレーション(図右上の青枠の表)で想定されていた変更が起こるはずです。
一方でこれによりデータAは共有されます。これはCPU0側の当初のシミュレーションでは想定されていなかったことです。このためADVはシミュレーションをやり直し、直前のCPU1によるAの共有という結果を反映させ、CPU0のストア命令に対する新しいシミュレーションを作製します。これによりCPU0側が後続して実行されても、正しいシミュレーションが行えます。
デバッガによるバグ検知 1. アドレスの混同
ここからは実際にADVを使ったデバッグを見ていきます。
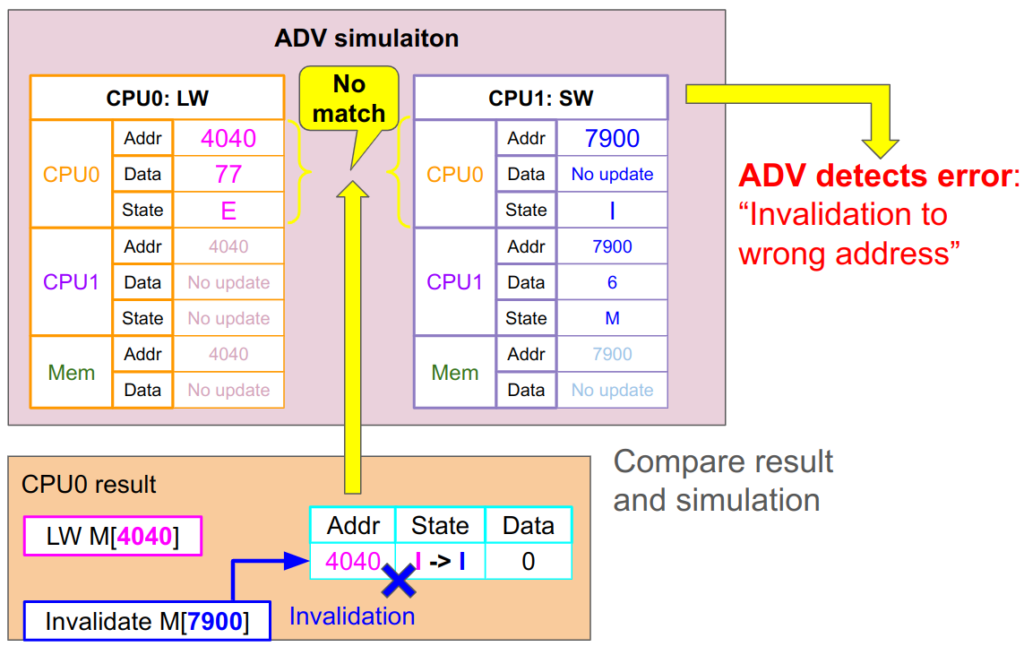
デバッグ編1でプロセッサ本来の処理のアドレスとスヌーピングのアドレスを混同するバグがありました。これにより間違ったアドレス(固有プロセスの0x4040)に対してInvalidationが行われていました。
ADV1はCPU0の固有プロセスであるLWのシミュレーションと、Invalidationの発行元であるCPU1のSWのシミュレーションを行います。それぞれ、LW側は「CPU0ではアドレス0x4040がE状態になる」という変化を予測し、SW側は「CPU0ではアドレス0x7900がI状態になる」ことを予測します。
しかし実際にCPU0で起こった結果は「アドレス0x4040がI状態になる」というものでした。これはどちらの命令のシミュレーションとも一致しません。ADVはこれを検知して、速やかに「間違ったアドレスへのInvalidationがあった」というエラーを報告します。設計者は直前の命令を確認するだけで、すぐにアドレス選択のバグを発見できます。
デバッガによるバグ検知 2. 連続実行すべきチャネルの分割
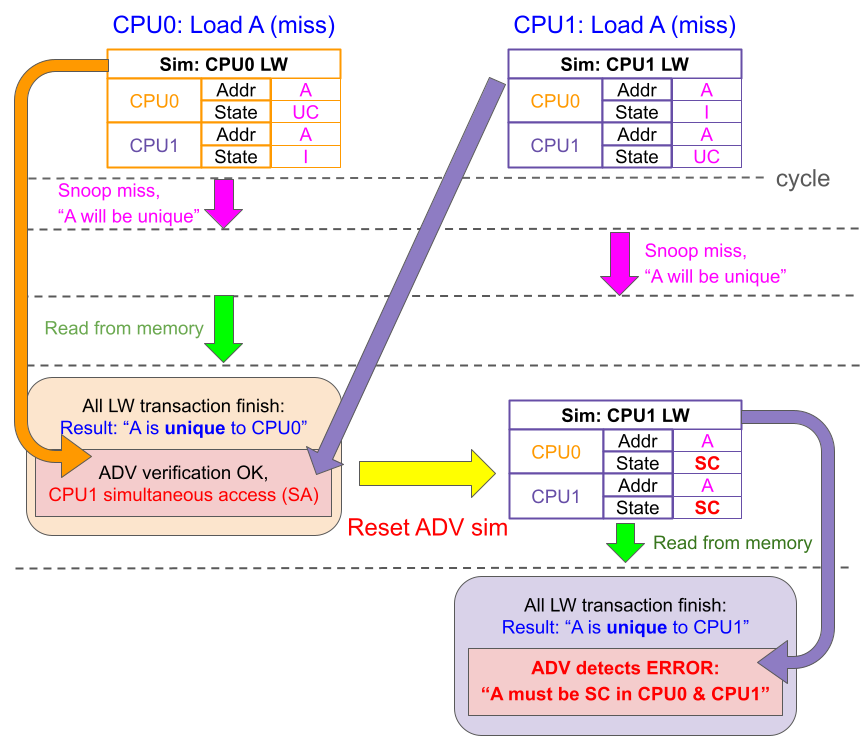
バスの異なるチャネル間でも同じサイクルでは同じアドレスは使っていなくても、トランザクションが終わっていないのに他のトランザクションが同じアドレスを使うとエラーが起こるというバスの同時アクセスのバグがありました。
この時、ADVは各CPUごとにシミュレーションを作ります。そしてCPU0側のロードが先行します。このロードのトランザクションは途中でCPU1からのスヌーピングを受けますが、ひとまず成功してCPU0のシミュレーション通りの結果となります。ここでADVがCPU1もAに関するロードをやっていることに気付き、CPU1のシミュレーションを再実行します(図中赤字の「Reset ADV sim」のところ)。
CPU1の再シミュレーションでは直前のCPU0のロード結果を反映し、「CPU1自身のロードで、CPU0、CPU1ともにAをSharedClean(MOESIのS)で保持する」と予測します。しかし実際のバグのある実行結果はどちらもUniqeu状態のままでした。そのためADVは予測と違うとエラーを吐き、使用者はすぐにスヌーピングが上手くいっていない = CPU0のトランザクションが終わる前にCPU1のスヌーピングが行われてしまっているというバグを特定できます。
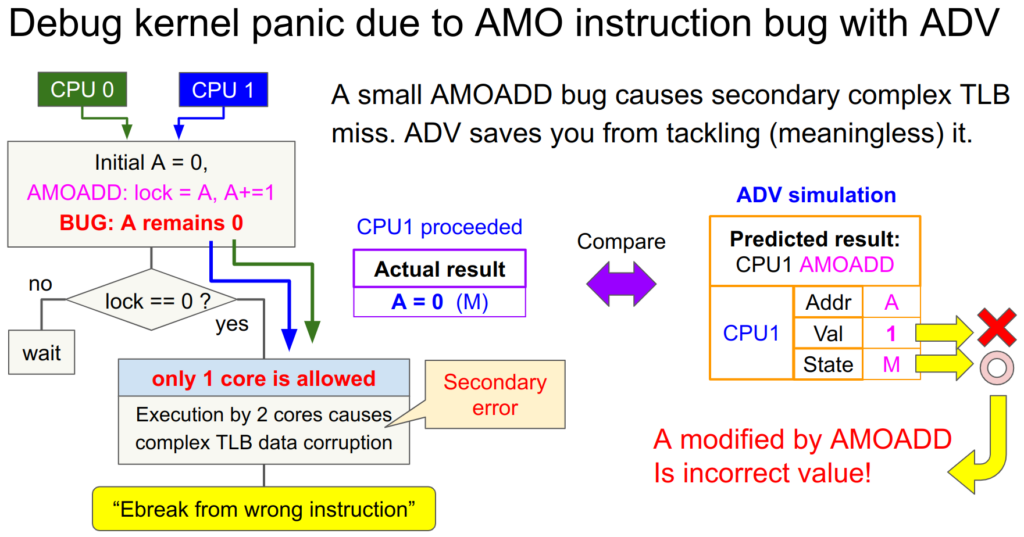
デバッガによるバグ検知 3. AMOのバグによる複雑なLinux初期化エラー
この記事の最初のAMO命令のバグにより引き起こされたLinux初期化エラーも特定できます。問題のバグはAMO命令が新しい値をストアできていないという些細なバグが元凶でした。ADVはこのAMOADD命令の結果を予測し、「AMOADD命令により初期値0に+1された値1がAにストアされる」ことを予測します。
しかし実際にはこれは起こらずAは初期値0のままでした。ADVはこれを検知して「AMOADD命令の結果の値がおかしい」ことを通知します。使用者はこれを見てすぐに元凶となるAMO命令のストアのバグを直すことができます。面倒極まりないTLBやら何やらの二次的エラーに惑わされなくてすみます。
そんなこんなでデバッガを使ったところ、わりと効率的にデバッグ作業が進みましたとさ。
おわりに
さて、色々ハードやらソフトやらデバッグをやってとりあえず2コアのRISC-Vマルチコアは形になりました。信号1つやほとんど起こらないような些細な抜け漏れのために、大掛かりな変更を余儀なくされることもありました。
こんな初歩の初歩なマルチコアで悪戦苦闘している自分にとっては、IntelやarmとかNvidiaの設計者ってとんでもないですね。設計する前から信号のあらゆるレベルの相互干渉が視えていたりするのでしょうか。きっとバグの回避が別のバグを引き起こすみたいなエンジニアの円環の理から解脱した人々なんでしょうね。
