皆様こんにちは。18のhiraです。
僕はコンピュータ工学をやっているつもりで、研究ではRISC-Vのプロセッサをマルチコアにする作業をしていました。とはいえ、どういう機能を追加する必要があるのか、それはハードで実装するのかソフトで対処するのかなど戸惑ったことも多かったため、備忘録として残しておきたいと思いました。

なんでそもそもマルチコアにしたい?
マルチコア(マルチプロセッサ)は読んで字のごとく、プロセッサが複数あり、同時並行でそれぞれが処理を進めることができます。これには主に以下の3種類の用途があります。
- 大規模な1つの計算を分担して行う場合
画像処理、大規模な配列のソートや検索、グラフツリーの作製流体シミュレーションといった計算は計算量が膨大です。しかし画像の左上部分と右下部分を手分けして処理するといった、座標や配列の担当領域を各プロセッサに割り当て、同時並行で処理することができます。これにより同じ時間でもプロセッサの数だけ処理量を増やせます。 - プロセッサごとに別々のタスクを行う場合
プロセッサ0には音楽の処理を進めさせ、プロセッサ1にはエクセルの処理を行わせるような別々の処理を行わせることもできます。これによりプロセッサ0は音楽の処理だけを行えばよいため、音楽を中断して他の処理をする必要はありません。
他にもメインの処理をプロセッサ0に行わせ、プロセッサ1には0の動作監視を行わせる構成もあります。もしプロセッサ0に異常が起こり停止してしまっても、プロセッサ1がその異常を検知して緊急事態対応を行うことができます。 - ある処理が得意な専用プロセッサに処理を投げる場合
データの暗号化やFFTのような信号処理は「掛け算を10回行う」などその手順が決まっています。そのため汎用プロセッサで1つ1つその処理を再現するよりも、その処理専用に演算器の種類と接続を最適化した専用プロセッサを作る方が数百倍以上の高速・低消費電力化が可能です。
メインの汎用プロセッサは複雑なゲームの処理をこなし、紋切り型の通信の暗号化処理は暗号化専用プロセッサに任せることで効率的な処理ができます。
既に1nm級の半導体製造プロセスが進んでいるとはいえ、1つのプロセッサの性能は限界に近づいています。そのため複数のプロセッサで効率的に処理を分散することで全体の性能向上を狙うのが近年のトレンドとなっています。
使用環境
プロセッサの設計は僕の所属している研究室で開発しているC2RTLというツールを使用しました。
名前の通りCコードでプロセッサの振る舞いを記述すると、RTLに変換されるという高位合成に似たツールですが、以下のような利点があります。
- 一般的なプログラム同様ループされる1ステップの内容の記述でよく、パイプラインをどこで区切るかといったサイクルレベルの動作指定をしてCからVerilogへ変換できる
- VerilogレベルのC言語(RTL-C)高精度・高速シミュレーションができるため高価なハード試作を減らせる
- 既存のソフトやデータを併用したシミュレーションができるため、より実用的な環境で実験できる
- 様々なプロセッサを簡単に一から作れるため、AIや自動運転のようなアルゴリズムが乱立する状況でもハード化に挑みやすい
- コードやソフトウェアデバッグ手法がそのまま使えるので、アルゴリズムを書いたプログラマがそのままプロセッサ化できる
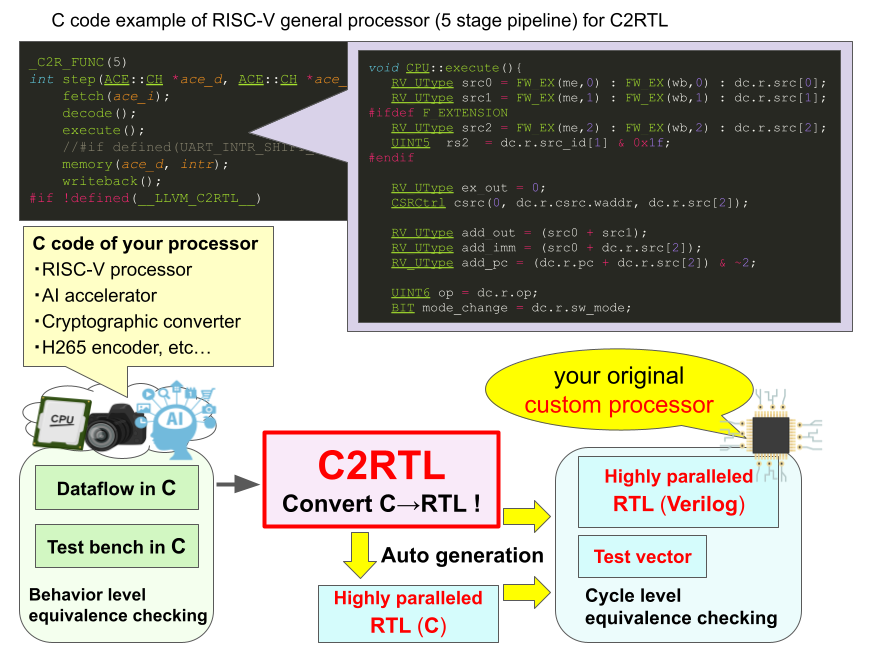
研究室としてはこのようなツールを使い、プロセッサ本体やAIや暗号、指紋認証のアクセラレータ等を作ったりしています。
このマルチコア化始めた時点で1コアでのLinuxのブートはできていたため、自分は2コアにする作業を行いました。設計では32bitの2コアプロセッサにしましたが、64bitでもだいたいは同じだと思います。
マルチコア化するためには何が必要?
RISC-Vの4コアのマルチコアシステムは以下のような構成となります。
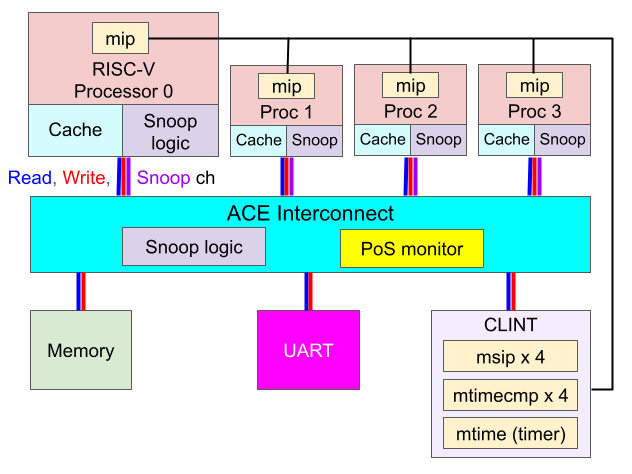
それぞれの機能は以下のような機能を持ちます。
- RISC-V Processor x 4
このシステムには4つのRISC-Vプロセッサがあります。それぞれが別個にキャッシュを備えています。各プロセッサの「Snoop logic」は後述する「スヌーピング」という機能を行い、他のプロセッサとのキャッシュ同士でデータを送受信したり、書き換えの報告を行います。
またキャッシュに格納されたデータは、そのデータが共有されているか、書き換えられたかの状態を示す「MOESI」(後述)のようなキャッシュ状態を持っています。 - ACE Interconnect
ACEはArmが策定したデバイス間通信プロトコルであるAXIの拡張で、プロセッサ間でスヌーピングが適切に行われるように通信手順を定めたプロトコルです。本システムのバスはこのACEプロトコルに則り、信号の送受信を機能的に行うインターコネクトとなっています。
PoS MonitorはArmアーキテクチャ命令の排他制御(自分の動作中に他のプロセッサに干渉されていないことを保証する)命令に使われるもので、ここではRISC-Vの役割の同じLR/SC命令のために使用されます。なお各プロセッサにはEX monitorというものが備わっていて、これと連携してLR/SC命令を行います。 - Memory
普通のメモリです。AXIプロトコルの送受信に従って各デバイスにデータを渡したり、ライトバック(WB)を受け付けたりします。 - UART
コンソールへの表示やキーボード入力の取得をします。 - CLINT
Core Local Interruptで各プロセッサに割り込みの発生を通知します。各プロセッサはタイマ割り込みやソフトウェア割り込みの条件をCLINTに送ります。割り込み発生条件が満たされると、割り込み対象のプロセッサに割り込み到着通知を行います。
当然、システムによってはこれにGPUやスピーカーデバイスなど色々なものが加わったりしますが、最低限のものとしては上のような機能が挙げられます。
以下では各機能に関して説明します。
スヌーピングとキャッシュコヒーレンシ
スヌーピングはプロセッサ同士でキャッシュのデータを融通し合う仕組みです。メモリからのロードは時間がかかるため、高速にアクセスできるキャッシュ同士でデータを貰えれば効率的です。
下の図はプロセッサ0(CPU0)がデータAをロードする時にスヌーピングによりデータを取得する、snoop readの例です。
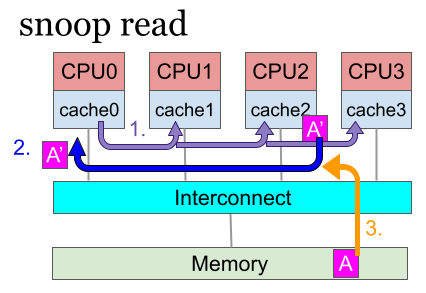
- CPU0はインターコネクトにデータAのロード要求をする
- インターコネクトは各プロセッサのsnoop chにスヌーピングの問い合わせを行う(紫矢印)
- ここでCPU2が既にAをキャッシュしていれば、snoop ch経由でCPU0にAを渡す(青矢印)。この時CPU2がデータAを値A’に変更していたら、変更後のA’がCPU0に送られる
- 誰もAを持っていなければメモリからAを取得する(オレンジ矢印)
snoop readにより、他のプロセッサが保持している最新の値が求まります。これにより「同じデータはどのプロセッサでも同じ値をもつ」ことが保証されます。これを「キャッシュコヒーレンシを保つ」と言い、グローバル変数はどのプロセッサでも同じ値であることが保証されます。
キャッシュコヒーレンシを保ちながらデータの値を書き換えるのがsnoop writeです。
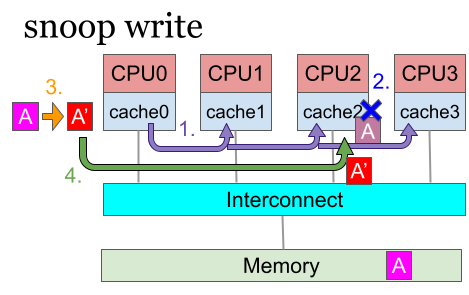
- CPU0はデータAを値A’に書き換えたいが、その前にまずインターコネクトにInvalidation要求を送る
- インターコネクトは各プロセッサのsnoop chにスヌーピングの問い合わせを行う(紫矢印)
- ここでCPU2がAをキャッシュしていたら、「他のプロセッサがAを書き換えるから、現在のAは使えなくなる」ことを判断する。CPU2は手元のAを無効化、Invalidationにより消去する(青バツ印)
- すべてのプロセッサからインターコネクトにInvalidation完了報告が来たら、CPU0にInvalidaiton完了報告をする
- この段階でAはCPU0しか持っていないことが保証される。CPU0はAをA’に書き換える(オレンジ矢印)
- もしCPU2が再度データAを使いたい時は、CPU2がsnoop readを行う。これによりCPU0が書き換えた最新の値(A’)のAがCPU2にも共有される。
スヌーピングプロトコルを使用する場合は、勝手にキャッシュのデータを書き換えることはできません。事前に他のプロセッサに問い合わせを行い、該当のデータをInvalidationしてもらう必要があります。これにより書き換えがあってもキャッシュコヒーレンシが保証されます。
システム図の各プロセッサが持っていた「Snoop logic」は、他のプロセッサからのスヌーピング要求に対応するためのものです。Invalidation要求を受けたら、キャッシュ中の該当データを消去し、ロード要求を受けたら該当データをインターコネクトに流します。
インターコネクト側のSnoop logicは各プロセッサから来たデータのロード要求を他のプロセッサへのスヌーピングへとつなげたり、誰もキャッシュしていなければメモリからのロードに切り替えるような交通整理をしています。
AXIとACE
このスヌーピングをするシステムを支えるバスの通信プロトコルがACEです。ACEは高速通信規格のAXIの拡張で、AXIはマスタ(*現在の名称はManager, M)側のプロセッサと、スレーブ(*現在の名称はSubordinate, S)間でのデータの送受信をしています。
例えばAXIにおけるプロセッサ(M)からメモリ(S)へのWrite Backを考えます。これには主には3つのチャネルで9つの信号が使われ、送信要求、受信準備完了、データ本体送信のやり取りを繰り返します。このS側への書き込みは以下の手順で行われます。
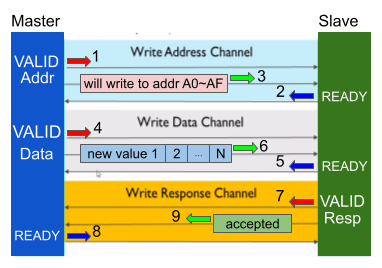
- MはWrite Address Chで接続要求であるValid信号を送る
- Sは1を受け取る。データ取得準備が出来たらReady信号を返す
- Ready信号を受け取ったMは、どのアドレスに書き込むかを指示するAddr信号を送る
- ここから実際にデータ本体の送信を行うWrite Data chが使われる。Mは送りたいデータが準備できたらValid信号を送る
- Sはデータ本体の取得準備ができたらReady信号を返す
- Mはデータ本体を送る。送りたいデータがバス幅を上回る場合は4~6を繰り返す
- データ本体の送信が終わったらWrite Response Chに移り、Sが結果報告をする。ここではまずSがValid信号を送る
- MがReady信号を返す
- SがResp信号を送り成功報告をして一連のWBを終了する
メモリからデータを取得するReadも基本的な動作は同じです。Mがアドレスを送り、それに対応するデータがS側からValid-Ready-Dataのやりとりで送られます。この一連のWrite address chからWrite Response chのやり取りをまとめて1つのトランザクションと呼びます。トランザクションにも種類があり、Readをするトランザクションもあります。
AXIではRead ch、Write chの2つを使いましたが、ACEはこれに加えSnoop chが追加されています。Snoop chはインターコネクトと各プロセッサをつなぎ、Valid-Ready-Dataのやり取りを行います。
例えばM0がデータAを書き換える時のInvalidaitonにおいては、以下のようにSnoop用chを使います。
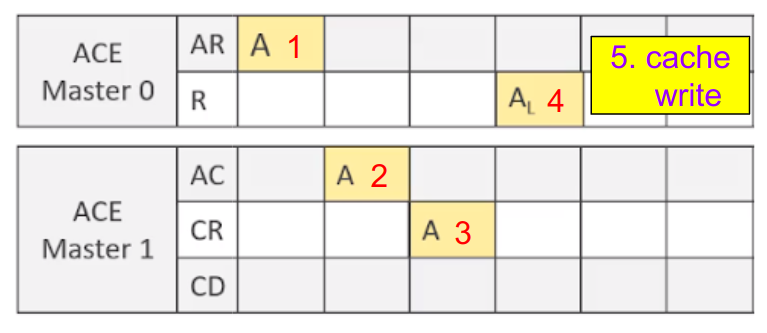
- まずRead Address ch (AR)でアドレスをインターコネクトに送る
- インターコネクトはM1のSnoop Address ch (AC)にInvalidaitonのためのスヌーピング要求を送る
- M1のInvalidationが完了したらSnoop Response ch (CR)でインターコネクトにスヌーピング完了報告をする
- すべてのMのInvalidaitonが完了したら、インターコネクトはRead Data ch (R)でM0にInvalidation完了報告を送る
- M0がキャッシュ内のAを書き換える
ここではデータの転送(Read)とInvalidation(Unique化)とを1度に行っています。そのためこの一連のやり取りは「ReadUniqeuトランザクション」と呼ばれます。
スヌーピングにより他のMからデータをもらう場合は、CRで「自分がそのデータ持っているよ」の返信を受け取り、Snoop Data ch (CD)でデータを送ります。インターコネクトはCDから流れてきたデータをRに転送して、M0にデータを供給します。この共有のためのロードは「ReadSharedトランザクション」と呼ばれます。
キャッシュ状態 (MOESIプロトコル)
キャッシュ中の各データは、それが書き換えられたものか、他のプロセッサに共有されているかの状態フラグも持っています。その状態フラグとして多用されるのがMOESI状態です。MOESIは、Modified、Owned、Exclusive、Shared、Invalid状態の5状態でキャッシュの各データを管理します。
MOESIはそれぞれ次の様な状態を示します。
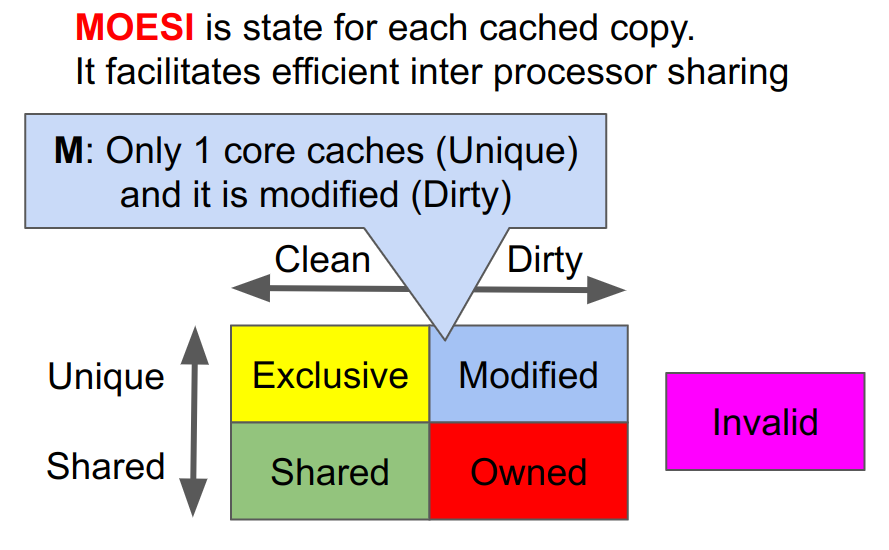
- Exclusive: 自分だけがキャッシュしていて、取得してから自分は書き換えていない
- Shared: 他のプロセッサも同じデータをキャッシュしている可能性がある。取得してからは自分は書き換えていない
- Modified: 自分だけがキャッシュしていて、取得した後に自分が書き換えた
- Owned: 自分が書き換えた後、他のプロセッサのキャッシュに共有された
- Invalid: 無効状態。キャッシュしていないことと同じ
このためMOESIはデータを自分が書き換えた(dirty)か、共有されているか(shared)かを表しています。同じデータAのコピーでもプロセッサごとに異なるMOESI状態を持ちます。またACEプロトコルでもMOESIと同じキャッシュ状態を想定していますが、こちらは分かりやすくUnique-Shared、Clean-Dirtyを組み合わせた表記となっています。例えばOwned状態はACEでは「SharedDirty」状態と表記されます。以降では文脈によってMOESI、ACE表記を両方使いますが、どちらも同じもとして扱います。
例えばM0がキャッシュミスしている(=Invalid)Aに値6をストアする状況を考えます。この時M1がAを値5のUniqueDirty (=Modified)状態で保持している(M1がA=5に書き換えた後誰も共有していない)とします。この時M0のストアにより各キャッシュ状態は次のように変化します。
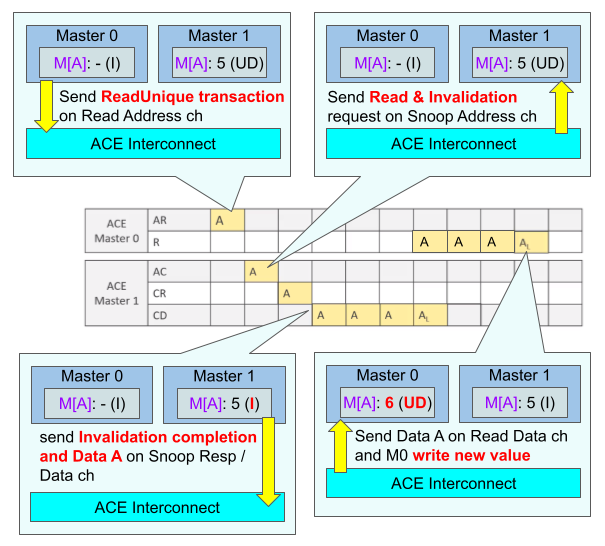
- M0はストアする前にAをロードする必要がある。インターコネクトにロード要求を送り、M1にスヌーピングが送られる
- この時M1のデータAがM0に送られるが、同時にM0がストアして書き換えるためにInvalidationも同時に行われる。このためM1のAはInvalid状態に変更される。そしてデータAがM0に送られる
- M0はデータAとスヌーピング完了報告を同時に取得する。そしてM0が新しい値6をAにストアする。これによりM0だけが書き換えられた値6のデータAをUniqueDirty状態で保持する
もしM0がただデータAをロードするだけならばInvalidationする必要はありません。その場合はスヌーピングによりM1のデータAはSharedDirty状態になり、M0のデータAはSharedClean状態になります。このように一度でも書き換えが行われたら、Dirty状態で保持するMがただ1つだけ存在します。Dirty状態はメモリにWBする必要性を意味し、Dirty状態のデータがキャッシュから追い出される際は、WBをして書き換えられた最新の値をメモリに反映させる必要があります。
RISC-Vの排他命令とACE
マルチコアでは上記のようなスヌーピングにより、他のプロセッサからの干渉を受けます。そのため自分が書き換えた後、勝手に他のプロセッサから書き換えられてしまい、想定と違う値になってしまうという状況が生じかねません。RISC-Vの排他命令はそのような事態が生じていないかを確認しながらロード・ストアを行い、干渉がないことを保証する命令です。
排他命令にはAMO命令とLR/SC命令の2つがあります。
まずAMO命令はロードとストアを1度に行う命令です。レジスタにメモリからのデータを読み取り、同時にレジスタのデータをメモリに書き込みます。
例えばamoswap命令はレジスタのデータとメモリのデータを1命令で交換します。以下の図の例ではレジスタx[rs2]の値がメモリM[x[rs1]]に格納され、メモリM[x[rs1]]のデータがレジスタx[rd]に格納されます。この間に使用しているデータが外部からのスヌーピングの影響を受けなかったという証明の結果がレジスタx[rs2]に格納されます。キャッシュを備えたシステムの場合、メモリの代わりにキャッシュとの読み書きが行われます。
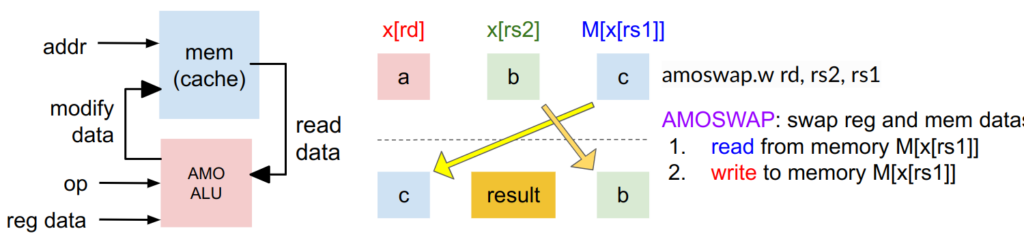
このAMO命令の動作はACEにおけるReadUniqueトランザクションに良く対応しています。
続いてLR/SC命令です。「パタヘネ」などの教科書でのMIPS版のLoad-linked / Store-conditional と同等のもので、以下のような処理を行います。
- あるプロセッサ0がLR命令を発行しデータAをロードする。同時にAを「予約 (reserve)」する
- もし他のプロセッサがAを書き換えたら、プロセッサ0のAの予約を取り消す
- プロセッサ0がSC命令を発行しデータAを書き換えようとする。もし予約がまだ有効であればストアを行う。予約が取り消されていればストアを行わない。ストアが成功したら結果レジスタにゼロを入れ、失敗したら非ゼロの値を入れる
ARMアーキテクチャではLR/SC命令と同等な命令にLDREX/STREX命令があります。LDREX命令では予約情報をプロセッサ側のExclusive Monitorとインターコネクト側のPoS Monitorに保持(1にセット)します。もしスヌーピングやインターコネクトに接続した他のデバイスからの予約データ変更があったら、それぞれのモニタの予約が取り消し(0)になります。ストアであるSTREX命令が各モニタを確認し、両方共1(予約有効)であればストアをします。

LDREX/STREX命令にRISC-VのLR/SC命令をそれぞれ対応させることができます。ACEのSTREXの成否判定のゼロ/非ゼロを反転させればLR/SCの結果レジスタの値に流用させることができます。
CLINTによる割り込み
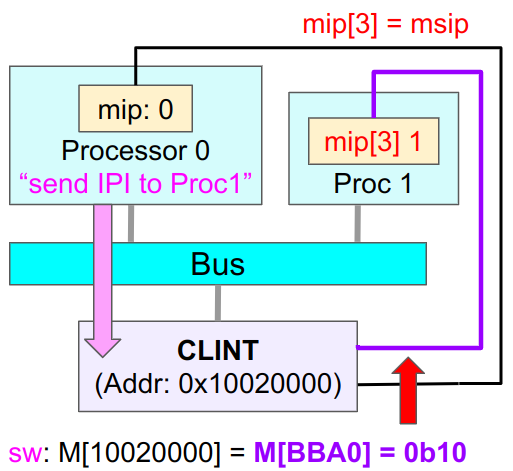
CLINTは割り込みに関するレジスタを持っていて、このレジスタの状態に応じて各プロセッサに割り込みを送ります。この通知は各プロセッサのCSR:mipレジスタを書き換えます。mipレジスタは割り込みの種類ごとに対応するビットを持っていて、どのビットが立ったかでどの割り込みを実行するかを判断できます。
例えばProc0がProc1にソフトウェア割り込みを送りたい場合、CLINTのアドレス:0x10020000にストア命令によりソフトウェア割り込み用のデータ値:0b10 (図のメモリBBA0番地の値)を送ります。この値は割り込みを送りたいプロセッサに対応するビットが1になっていて、ここではbit 0がProc 0に、bit 1がProc 1に対応しています。ここではbit 1のみが1なので、Interconnect経由でCLINTがそのデータを受け取ると、CLINTはProc1に対応するmsipレジスタをオンにします。これがProc1に伝わり、Proc1のmipレジスタのmsipに対応するビット値が変更され「割り込みが来た」ことを通知します。
システム図にあったCLINT中のmtimeとmtimecmpはタイマ割り込みに関するレジスタです。mtimeは現在の時間で1サイクルごとにインクリメントされます。mtimecmpはタイマ割り込みの発生時間(サイクル)を指定するもの、いわば目覚まし時計の鳴るタイミングです。各プロセッサはCLINTに次のタイマ割り込み発生時刻を送り、CLINTはそれをmtimecmpに登録します。mtimeが指定されたmtimecmpの時間になったら、msipと同じようにターゲットのmipレジスタのタイマ割り込み発生ビットを立て、割り込み発生を通知します。
このCLINTのアドレスは設計されたハードにより異なります。ベアメタルでタイマ割り込みプログラムを各場合は、インラインアセンブラ等で直接CLINTのアドレスと送る値を指定してストア命令:swを記述する方法が考えられます。一方Linuxで使用する場合は、Linuxの「デバイスツリー」というファイルにCLINTのアドレス等の情報を記述します。Linuxはこのデバイスツリーの情報を見て、CLINTの使用方法を把握しSWに設定するCLINTのアドレスといった内部のプログラムを調整してくれます。
プロセッサ設計にもよりますが、このCLINTのSWはキャッシュに書き込むのではなく、直接Interconnectに送られます。この実装としては、アドレスの範囲によってキャッシュへ書くか、直接Interonnectに渡すかの制御が考えられます。私の実際の実装ではアドレスが0x8…から始まるものはDキャッシュに書き、0x1から始まるものは直接Interconnectに送りました。
CSR:mstatusによるアドレス変換の実施
OSは複数のプログラムを並行して動かすため、各プログラムが使用するアドレスを元の値から変更してずらしています。これをアドレス変換と言い、アドレス変換をするための専用ハードウェア(MMU、TLB)が存在します。アドレス変換の方法に関しては過去のブログをご覧ください。
RISC-Vではメモリアクセスする際にアドレス変換を実施するかしないかを判断する機能があります。アドレス変換が実施されるのは以下の2通りの状況です。
- CSR:satp の MODE ビットが実行したい変換方式 (Sv32 等 ) に固有の非ゼロの値の時
- CSR:mstatus の MPRV ビットが 1 の時
以上の状況でMMUが呼び出され、与えられたメモリのアドレス(仮想アドレス)が物理アドレスに変換されます。
OSが稼働中の時は主に1によるアドレス変換が実施されます。RISC-Vの場合はスーパーバイザモード、ユーザモードではこの方法によるアドレス変換が実施されます。一方2は限定的な状況で用いられ、特にマシンモードが一時的にアドレス変換を実施する際に使用されます。
参考サイト・資料
スヌーピング、ACE、MOESIの説明にはarm Trainingがおすすめです。1年で99ドルかかる会員サイトですが、armの各種プロトコルや開発ツールの使用方法、バスやarmプロセッサのIPの説明などが短くて分かりやすい動画で多数紹介されています。なんちゃらすぺしふぃけーしょんとかいうACEのプロトコル仕様書を頭から読むよりも遥かに分かりやすいです。
またRISC-V CPUの自作には『RISC-VとChiselで学ぶ はじめてのCPU自作』がおすすめです。Chiselというわりと簡単(*私以外の人類の皆様には)なハードウェア記述言語を使い、実際にRISC-Vのコードが動くプロセッサを作ります。
作るプロセッサも本格的で、5段パイプラインや、応用としてベクトルプロセッサ、カスタム命令という先進的な機能を搭載しています。それにも関わらず説明はとても分かりやすく、300ページの技術書ですがすらすらと、ステップ・バイ・ステップで進めることができます。パイプライン搭載プロセッサも300行程度で書けました。ホントにAmazonで星100くらいあげてもよい本だと思います。

